
Is Your Company Doing AI Or Statistical Regression?
Why Statistical Regression Techniques blurred into AI

Statistics is not AI.
AI is a wide-ranging term that means everything and nothing simultaneously. I recall back in 2017 when discussing an “AI” feature, I wanted to productise to a now dear friend, Rosario. He became very irate with my use of the phrase “AI.” He angrily stated that I was using statistical regression and that my product involved no AI whatsoever. Naturally, he was right, and as I care far more about not being wrong than being right, I quickly adjusted my language around the product.
The conversation has stayed with me ever since, and I often find myself in this AI euphoria, attempting to correct people who make the same mistake. However, the world has changed, and undoubtedly, one of AI’s cornerstones is based on many forms of statistical analysis and regression. In short, statistical analysis & regression are a discipline related to a collection of mathematical methods that rely on historical data patterns to summarise the state of the data and possibly derive future states of yet unproduced data (Statistical Analysis & Regression is better explained here).
So why is it so common to confuse statistical modelling with AI? Let’s try to understand how it’s used and where the lines blur with a simple thought experiment.
The Chess Challenge
This is a hypothetical chess challenge. No kings are on the board, so it’s technically not a legitimate chess game. The board is set up for this challenge. Each piece can only move like they do in a real game. The game is stacked in favour of black. If either of the pawns progresses to the 8th row, they can be swapped for another piece. White’s goal is to prevent this.
I am playing the black pieces, and the AI is playing the white. It’s the AI’s go. The AI has been instructed to at least get a draw. To do this, the AI will need to take both pawns, ideally before they can reach a8 and g8, respectively.
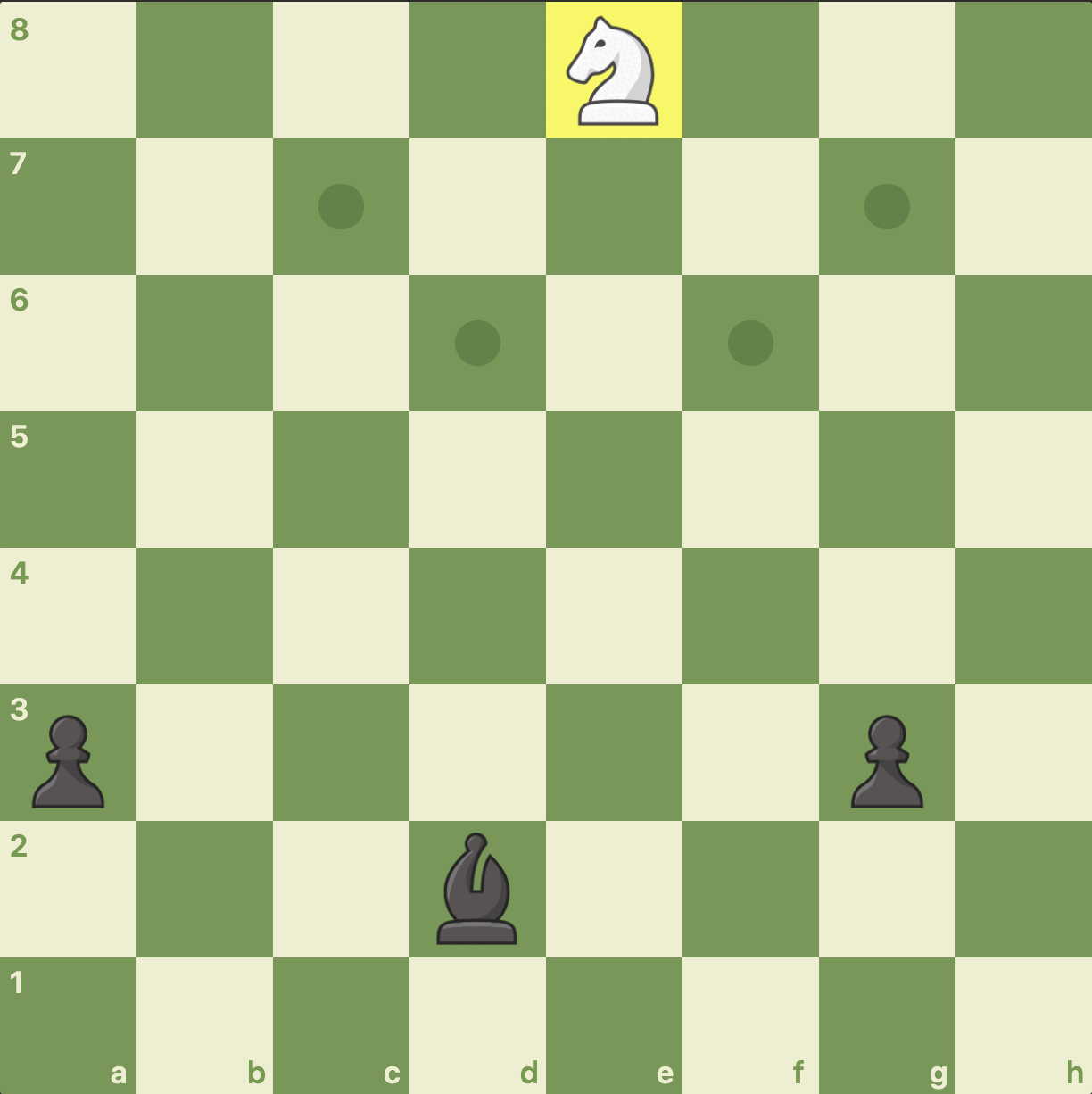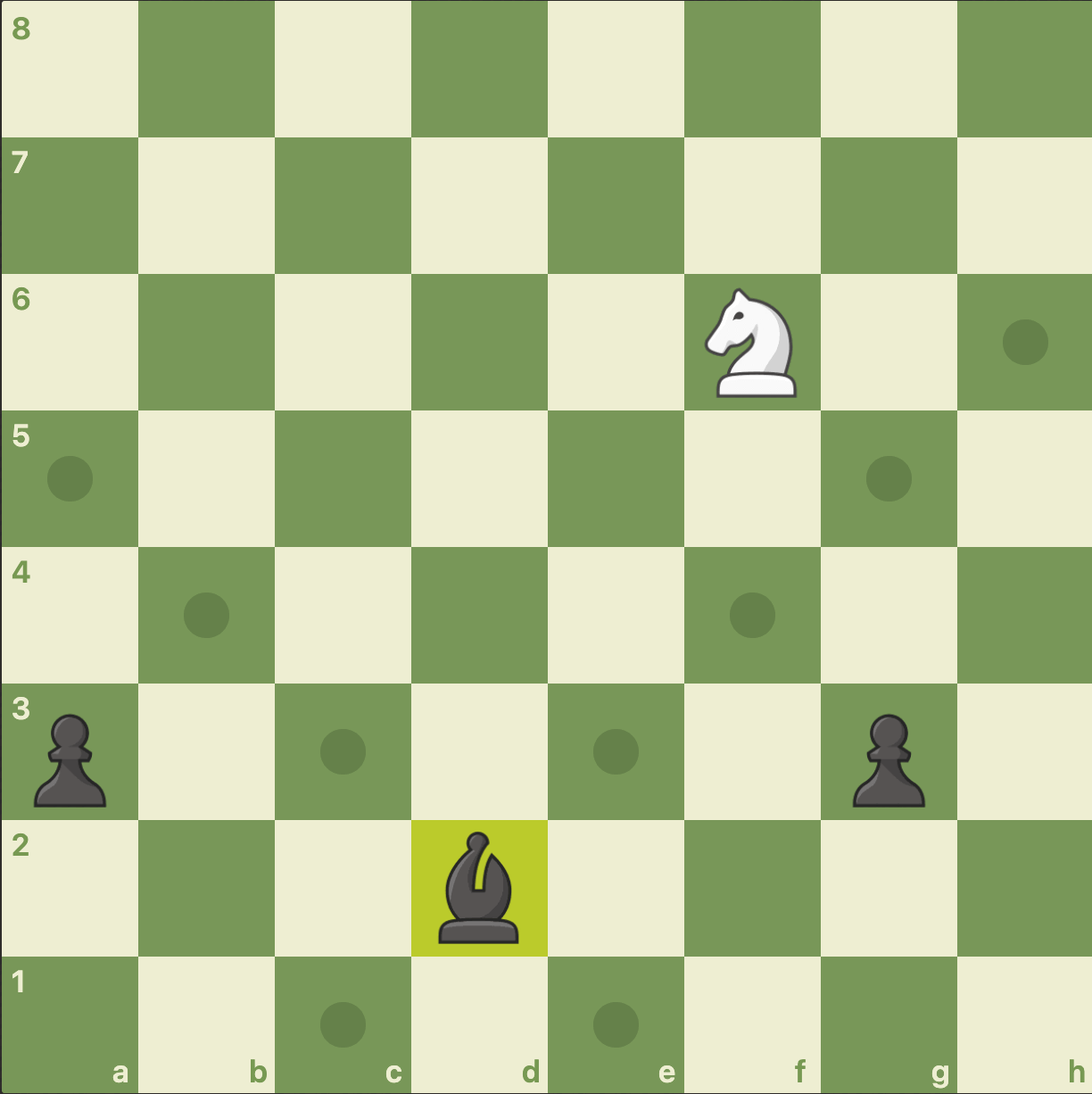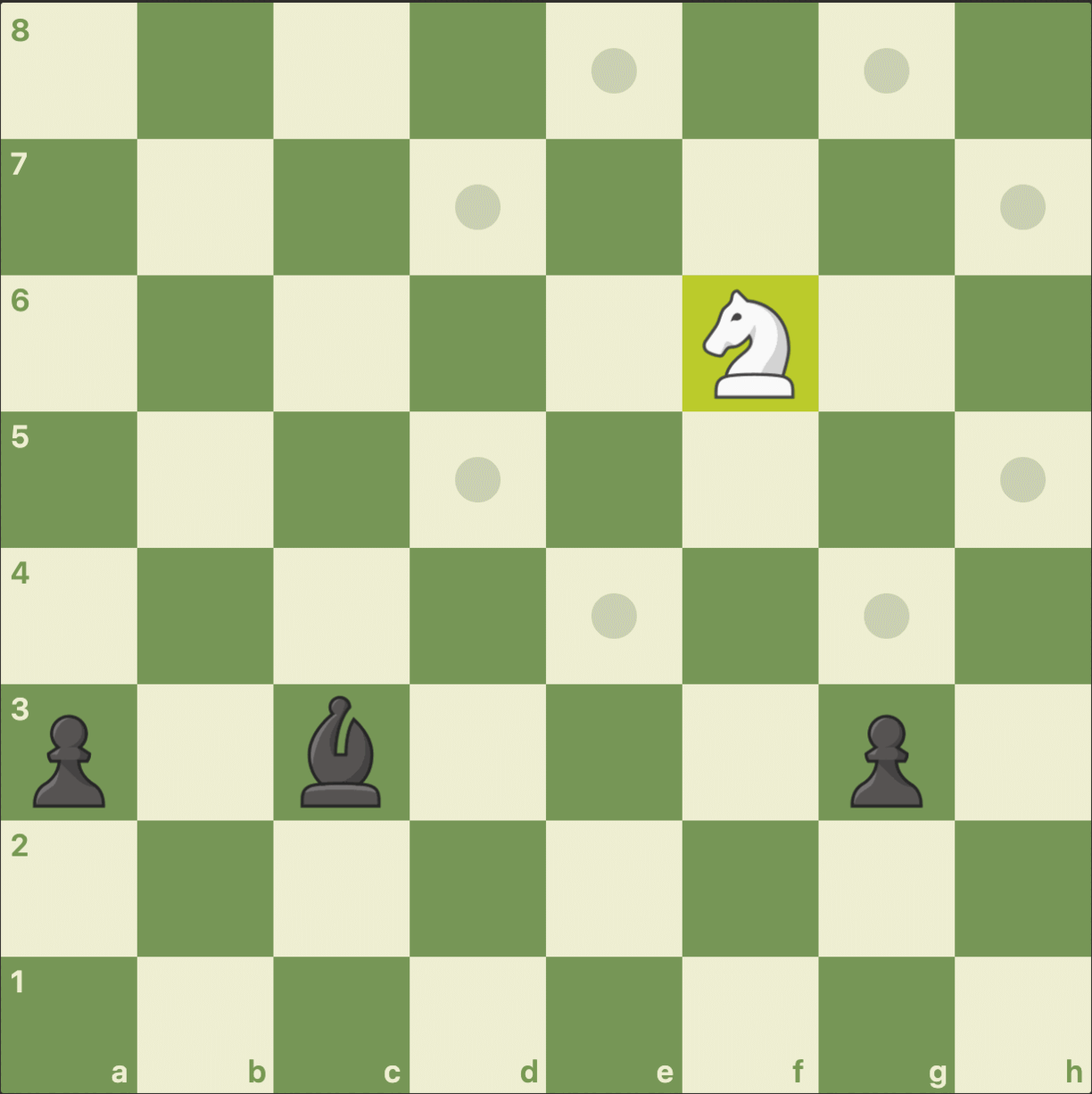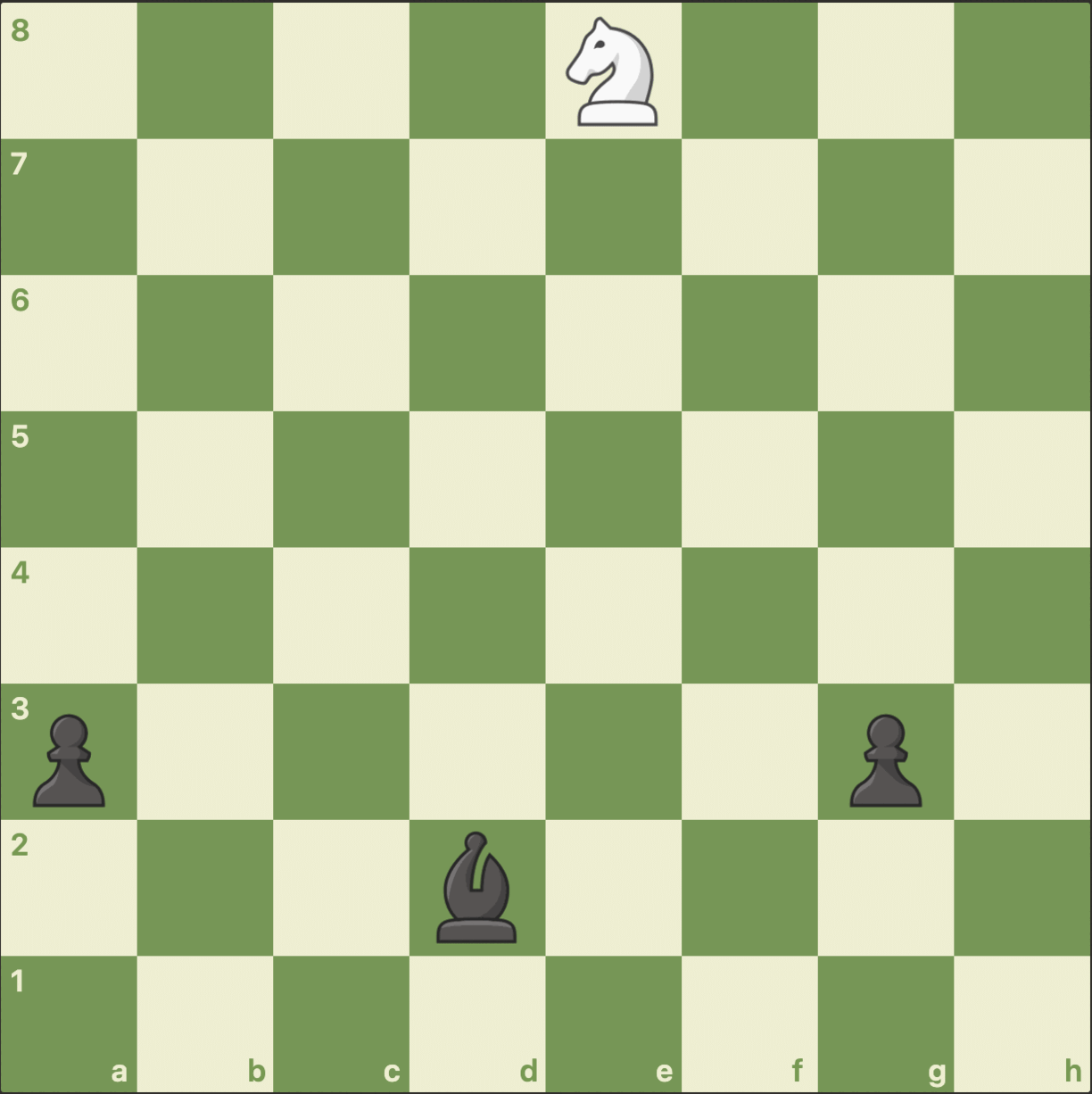
It’s the AI’s turn first, and the knight starts on e8. In the above GIF, you can see how the four-move game plays out. Each move is preceded by a frame that shows the potential moves the player could make.
Before continuing, consider the AI’s chances of drawing the game. Instictively what do you think the odds are?
We stopped playing after four moves with all the pieces in the same position they were in when we started the game.
The Challenge:
Looking at the Knight’s initial and final position. Has the AI’s chances of drawing the game changed?
Remember that all the pieces on the board’s initial and final positions are identical. Take a moment to consider, then vote below.
All Statistics Are Not The Same
Our current model is limited in that it only considers the piece’s movement on the chessboard1. However, many more factors affect the eventual outcome. For example, the model does not consider me a Human and it’s an AI.
Humans: The Series of Errors
We constantly make errors. Whether it’s while walking, talking, grabbing and carrying objects, typing or writing. Not a single waking hour goes by without us adjusting to a miscalculation. Psychologist Donald Broadbent proposed in his work “Perception and Communication” foundational models for understanding human error, distinguishing between slips (errors in execution) and mistakes (errors in planning).
Machines don’t have this problem.
With this new information, look at the Knight’s initial and final position. Has the AI’s chances of drawing the game changed?
The skilled statisticians among us will likely have immediately answered the challenge questions so far with little thought. Their practice and past experiences allow them to focus on the important aspects first, identifying those likely to have the greatest effect on the prediction. This skill is often later called "intuition.” More on that later.
Not all Data is the Same
The data I provided earlier was detailed and credible, complete with academic references and studies. Yet, like many statistical models, the appearance of reliability can be misleading. I presented information in a way that encouraged quick acceptance rather than critical analysis. Did you verify the studies? Question the cohort sizes? Read the actual papers?
This isn't a criticism - it's an observation of how we process information. We often accept it without interrogating its validity when presented with well-structured data. These human traits, known as “confirmation bias”2 or “belief perseverance”3, affect how we evaluate information and, consequently, how we make decisions.
Interestingly, modern language models exhibit similar behaviour, confidently presenting plausible-sounding information that may not be entirely accurate, a phenomenon often called "hallucination." But let’s try to stay on topic and return to our chess probability question to consider something more relevant to our analysis.
C & C
So we make errors, but does the information really affect our chess question? Far more important is my FIDE Elo Rating.
The FIDE Elo Rating System is a ranking system for chess players. It quantifies a player's skill level based on their game results against other rated players. The system determines player rankings, tournament seedings, and qualifications for titles such as Grandmaster (GM), International Master (IM), etc.
That said, I am a beginner. I have played four hours of chess. I do not know techniques or strategies and plan no more than three moves ahead.
With this new information, look at the Knight’s initial and final position. Has the AI’s chances of drawing the game changed?
This perfectly illustrates the correlation versus causation trap that plagues statistical models. My four hours of chess experience correlates with being a beginner, but does it cause my future moves to be poorer than a grandmaster? When building statistical models, we often focus on relevant data points (like time spent playing) while missing crucial causal factors (like the quality of learning, natural aptitude, or strategic thinking ability). This is why adding more variables to our models doesn't always improve their accuracy - correlation isn't causation, even when it feels like it should be.
The Complexity of Variables
The final factor is an admission. I was extremely intoxicated by alcohol when playing.
Fillmore, M. T., & Vogel-Sprott, ( M. (1999) in there article “Effects of alcohol on cognitive functioning” noted the effects of alcohol on cognitive functioning. It showed that alcohol impairs the ability to maintain attention and focus on tasks. Intoxicated individuals often exhibit reduced selective attention and increased distractibility, making it challenging to perform tasks that require sustained concentration. Oh… I forgot you know the misdirection trick now.
With this new information, look at the Knight’s initial and final position. Has the AI’s chances of drawing the game changed?
But here's where variables get messy. What does "extremely intoxicated" actually mean? Am I a frequent drinker with high tolerance or an occasional social drinker? Was this my first drink or my tenth? Had I just consumed the alcohol, or was I sobering up? Each of these hidden variables could significantly affect my chess-playing ability. This highlights a crucial challenge in statistical modelling - sometimes, what appears to be a clear data point ("extremely intoxicated") actually contains numerous hidden variables that could dramatically affect our predictions.
What’s The Point (The wrap Up)
Looking at our game, what started as a simple probability question (can the AI draw the game?), became increasingly complex as we added more variables. Each new piece of information changed our assessment, just like how statistical models change with data.
The Intuition Trap
Remember earlier when I mentioned intuition? I find it fascinating how humans develop "gut feelings" about things. My chess intuition (all four hours of it) might tell me a move feels right, but that's actually my brain running its own statistical analysis based on my limited experience. Here's the kicker. When we see GPTs making "intuitive" connections, we see something that looks like human intuition but is pure statistics. The model doesn't have an "aha!" moment like we do. It calculates probabilities based on patterns in its training data and how you react to its responses.
That is what is interesting about our current generation of Language Models that power the GPTs we commonly use today. They are called "AI," and at their core, they're incredibly sophisticated statistical engines. Instead of juggling a few variables like player position, skill level, and sobriety, they're simultaneously processing millions of data points.
Consider this: asking GPT’s are doing what we just did with our chess game but at a massive scale. They look at patterns in their training data and calculate probabilities.4 "Given all the times these words appeared together in my training data, what's the most likely next word?"
The Difference Between AI and Statistical Models
Remember my friend Rosario getting annoyed about calling statistical regression AI? Well, he had a point, but the lines have become blurrier. Today's language models are built on statistical foundations but have grown so complex that they can appear intelligent.
The key difference? Traditional statistical regression, like what we used in our chess example, works with clear, defined variables. We knew exactly what we measured (i.e. piece positions, player skill, alcohol consumption). However, modern language models deal with something far messier: human language and knowledge. They're still using statistical techniques, just with way more variables and much more sophisticated math.
Here's a simple way to think about it:
- Traditional Statistics: "Given these specific variables, what's likely to happen?"
- Modern Language Models: "Given everything I've seen in my training data, what patterns might be relevant here?"
Closing Thought
The next time someone tells you they're using AI in their product, maybe channel a bit of Rosario and ask: "Is it AI, or is it really good statistics?" The answer might surprise you, and that's exactly the conversation we need to have, so buy me a drink and let’s talk.
A massive thank you to Chess.com for providing the graphics.
In fact, some of you will have only considered the current position.
Our tendency to search for, interpret, and recall information in a way that confirms our pre-existing beliefs.
The tendency to maintain a belief even when presented with clear evidence that contradicts or disproves it.
This is a massive simplification, but this is for the wider audience, not the knowledgable