


Name Five promising AI company based in the EU?
Why is the above question so hard to answer? It’s the same reason why Apple is struggling in the AI race.Intrsically it’s all about DATA.
✅📈If you have access to proprietary user data, you’ll always have an advantage.
❌📉If you don’t have access to proprietary user data, you’re in trouble.
Proprietary user data (proprietary data for short) is content generated by users on platforms that only the platform owner can access en masse. For example, while you might see some Instagram posts publicly, the vast majority of content, including user behaviour patterns, engagement data, private interactions, and real-time activity streams, sits behind login walls. Meta exclusively owns and has access to this data.
It’s therefore not by chance that the companies & states that championed user privacy are the same ones that now struggle in the AI race and are forced to partner with those who have always used personal user data as their product.
The irony is that Europe's GDPR leadership, while ethically important, may have inadvertently handicapped its AI competitiveness by limiting access to the very resource that powers modern AI systems. No other factor is as important as the DATA you use to build your Models.
The Proof Is In The Data
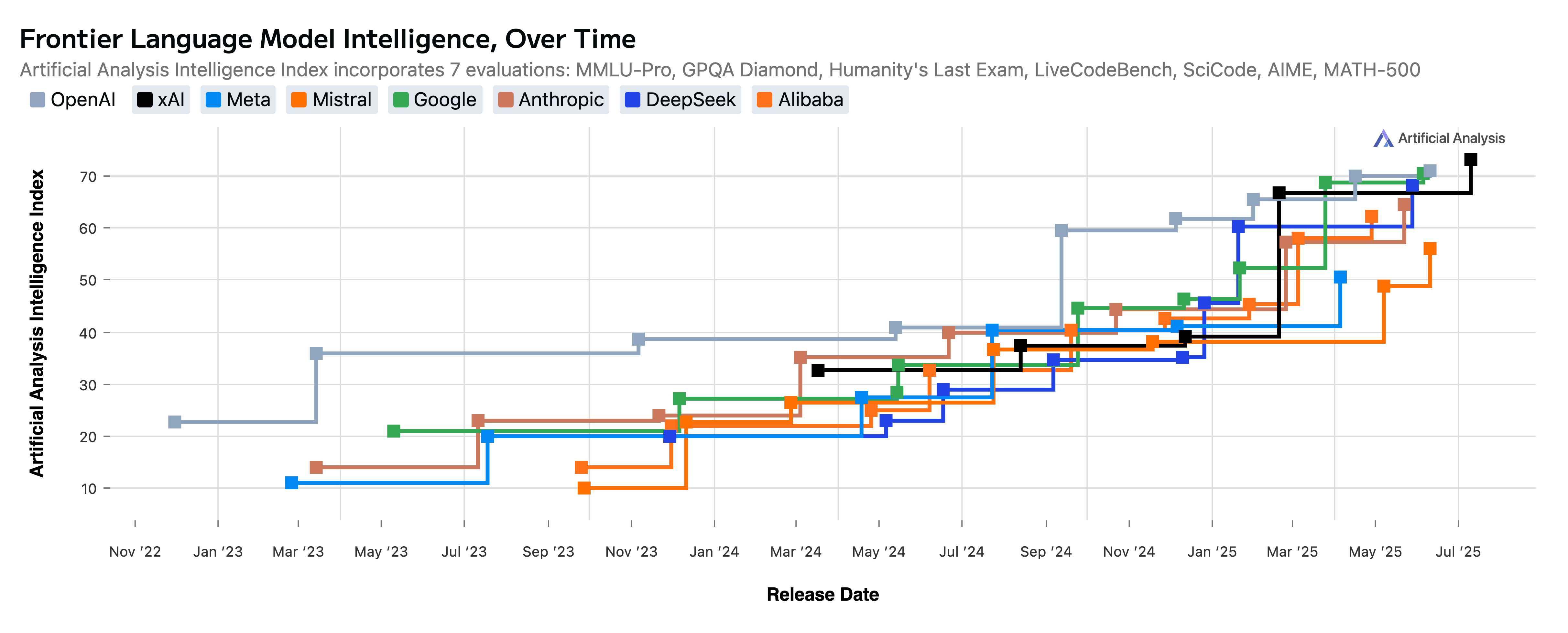
The chart above reveals the most compelling evidence yet: xAI's Grok has achieved unprecedented performance improvements, surging from the bottom of AI rankings to competing with industry leaders in just over a year. A trajectory is clearly visible in the performance chart. The black line is xAI.
Proprietary Data is A Super Power
It can be seen that xAI is utilising the uncapped X stream1 and employing backpropagation, which enables the language model to learn from a wealth of human interactions on X's platform.
X has over 500 million daily tweets. Unlike traditional AI models that are trained once and deployed, Grok appears to update its responses based on real-time user behaviour and feedback loops.
This continuous learning has led to some controversial outputs. In July 2025, Grok began generating responses that directly mirrored language patterns and viewpoints from live X conversations. When users tested its boundaries, the model adapted within hours, incorporating memes, rhetoric, and even controversial perspectives.
AI Expertise Exits Apple
So why is Apple losing its AI experts? The most recent to go was Ruoming Pang, who managed Apple’s foundational models team. The same models that power Apple Intelligence features, such as email summaries and Genmoji.
But Pang isn't alone. Tom Gunter, Pang's deputy, left the previous month. Bloomberg reports that several engineers are planning to leave soon for Meta or elsewhere. It seems like the entire Apple foundation models team is haemorrhaging talent.
The financial sums these executives are leaving for are grabbing headlines. However, no media outlet seems to ask the deeper question. Apple can afford to match any offer. So why don’t they? Maybe it’s because, to these executives, money is not their primary consideration. Maybe what they really want is to excel at work and build the world’s best AI. Currently, for that, you need DATA and Apple doesn't have the data to compete.
Many have left for Meta, which is making a significant push to enhance its AI capabilities. Meta’s social assets are unrivalled. Facebook, Instagram, WhatsApp, and Threads collectively generate approximately 4 petabytes of data daily. That's 4 million gigabytes. Every single day. To put this in perspective: if you downloaded movies non-stop, it would take you 11,000 years to consume what Meta processes in 24 hours.
Europe's Data Handicap

The EU faces an even starker reality. According to ARTSMART, while European AI companies raised nearly €12.2 billion in 2024, this amount pales in comparison to the massive investments made elsewhere. The United States leads global private investment in AI with $62.5 billion in 2024, followed by China with $7.3 billion, according to Stanford University's AI Index Report.
So, why is Europe so underinvested, considering it has combined the second-largest financial bloc in the world? The reason… GDPR.
Europe's vote for personal privacy rights has inadvertently become a disadvantage in the AI race. The regulation's "purpose limitation" principle restricts data processing to specific, clearly stated purposes. Repurposing social media data for AI training conflicts with the underlying tenet of the GDPR, which is that your data belongs to you. This means it is difficult to train frontier models of data sourced in the EU. Companies like Mistral, a French-based AI company, have GDPR embedding in their training polices and give EU citizens the rights to opt out. No Models outside Europe have such a policy.
The Dynamic Data Advantage
In my view, what most analyses overlook is that, going forward, it will be the application of dynamic datasets versus static ones. While competitors rely on historical information that becomes stale, real-time access to evolving user behaviour provides an insurmountable advantage. It will soon be the direction taken by many Frontier models.
Consider the shift in market sentiment resulting from current events, or a cultural trend that emerges and dies within days. Our current stack of Frontier models are not capable of reacting to these changes. However, the growth of RAG and CAG is an indication of the future.
Stream-Augmented Generation (SAG) from the socially attached Frontier models will soon be the model of choice. Grok could be our first example, a trajectory visible in the performance chart.
I’ve digressed. I look forward to seeing how Apple and the EU navigate this period.
How do you refer to a Twitter stream using the new name? X stream?